
This is the last type of histograms I used in my project of training an Adaboost classifier to distinguish two artistic styles.
The basic idea in this step is to build a histogram with the directions of the gradients of the edges (borders or contours). It is possible to detect edges in an image but it in this we are interest in the detection of the angles. This is possible trough Sobel operators. The next five operators could give an idea of the strength of the gradient in five particular directions (Fig 1.).
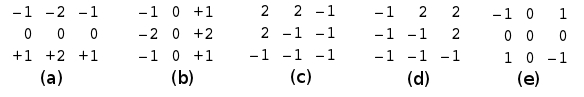
The convolution against each of this mask produce a matrix of the same size of the original image indicating the gradient (strength) of the edge in any particular direction. It is possible to count the max gradient in the final 5 matrix and use that to complete a histogram (Fig 2.)
In terms of avoiding the amount of non important gradients that could potentially be introduced by this methodology, an option is to just take into account the edges detected by a very robust method as the canny edge detector. This detector returns a matrix of the same size of the image with a 1 if there is an edge and 0 if there is not and edge. Basically it returns the contours of the objects inside the image. If you just consider the 1's we are just counting the most pronounced gradients.
I am also interested in calculate global and local histograms (I have already talk about this in previous posts). For example Fig 1, Fig 2 and Fig 3 presents the regions for three different type of region divisions: 1, 3, 8 respectively.



I found this code but I had to do several modifications because of my particular requirements. The most importants are:
- I need to work just with gray scale images
- I took out an initial filter that seems to be unnecessary
- I need to extract histograms of different regions
- I need a linear response. Just a vector with the responses together
I am posting the code with all the modifications:
# parameters
# - the image
# - the number of vertical and horizontal divisions
function [data] = edgeOrientationHistogram(im, r)
% define the filters for the 5 types of edges
f2 = zeros(3,3,5);
f2(:,:,1) = [1 2 1;0 0 0;-1 -2 -1];
f2(:,:,2) = [-1 0 1;-2 0 2;-1 0 1];
f2(:,:,3) = [2 2 -1;2 -1 -1; -1 -1 -1];
f2(:,:,4) = [-1 2 2; -1 -1 2; -1 -1 -1];
f2(:,:,5) = [-1 0 1;0 0 0;1 0 -1];
% the size of the image
ys = size(im,1);
xs = size(im,2);
# The image has to be in gray scale (intensities)
if (isrgb(im))
im = rgb2gray(im);
endif
# Build a new matrix of the same size of the image
# and 5 dimensions to save the gradients
im2 = zeros(ys,xs,5);
# iterate over the posible directions
for i = 1:5
# apply the sobel mask
im2(:,:,i) = filter2(f2(:,:,i), im);
end
# calculate the max sobel gradient
[mmax, maxp] = max(im2,[],3);
# save just the index (type) of the orientation
# and ignore the value of the gradient
im2 = maxp;
# detect the edges using the default Octave parameters
ime = edge(im, 'canny');
# multiply against the types of orientations detected
# by the Sobel masks
im2 = im2.*ime;
# produce a structur to save all the bins of the
# histogram of each region
eoh = zeros(r,r,6);
# for each region
for j = 1:r
for i = 1:r
# extract the subimage
clip = im2(round((j-1)*ys/r+1):round(j*ys/r),round((i-1)*xs/r+1):round(i*xs/r));
# calculate the histogram for the region
eoh(j,i,:) = (hist(makelinear(clip), 0:5)*100)/numel(clip);
end
end
# take out the zeros
eoh = eoh(:,:,2:6);
# represent all the histograms on one vector
data = zeros(1,numel(eoh));
data(:) = eoh(:);
The makelinear function doesn't exist in Octave. All it does is converting a matrix into a vector. If the function doesn't exist you can use the following function.
# makelinear.m # converts any input matrix into a 1D vector (output) function data = makelinear(im) data = zeros(numel(im),1); data(:) = im(:);